L3 的快,不等于结算风险消失
模块化 Layer 3(应用级 Rollup)的吸引力很明确:它可以把执行环境、费用模型、数据可用性和应用状态做得更专用,甚至在某个 L2 之上继续扩展。问题也同样直接:L3 的状态最终要通过 L2 再进入 L1,结算链路比普通 L2 更长。若没有嵌套 ZK 证明(Nested ZK Proof)或递归证明聚合,L3 的互操作就会在“用户看到已完成”和“结算层真正可验证”之间留下很大的时间差。
对 [AllSwap 跨链交换](/exchange-swap) 来说,L3 不是“更便宜的另一条链”这么简单。跨 L2/L3 交换需要回答:目标 L3 的预确认是否可被撤销?L3 proof 什么时候被 L2 接受?L2 proof 什么时候被 L1 接受?如果中间某层卡住,用户退款、Solver 垫付和资产退出应依赖哪个状态根?这些问题决定大额交易能否走快轨,还是必须等待完整证明链。
本文讨论模块化 L3 的证明结算模型,不把所有应用链、侧链和中心化执行环境混在一起。核心结论是:嵌套证明可以压缩验证成本和缩短最终可验证路径,但它不会消除数据可用性、字段转换、排序器预确认、跨层消息时钟和退款归因问题。
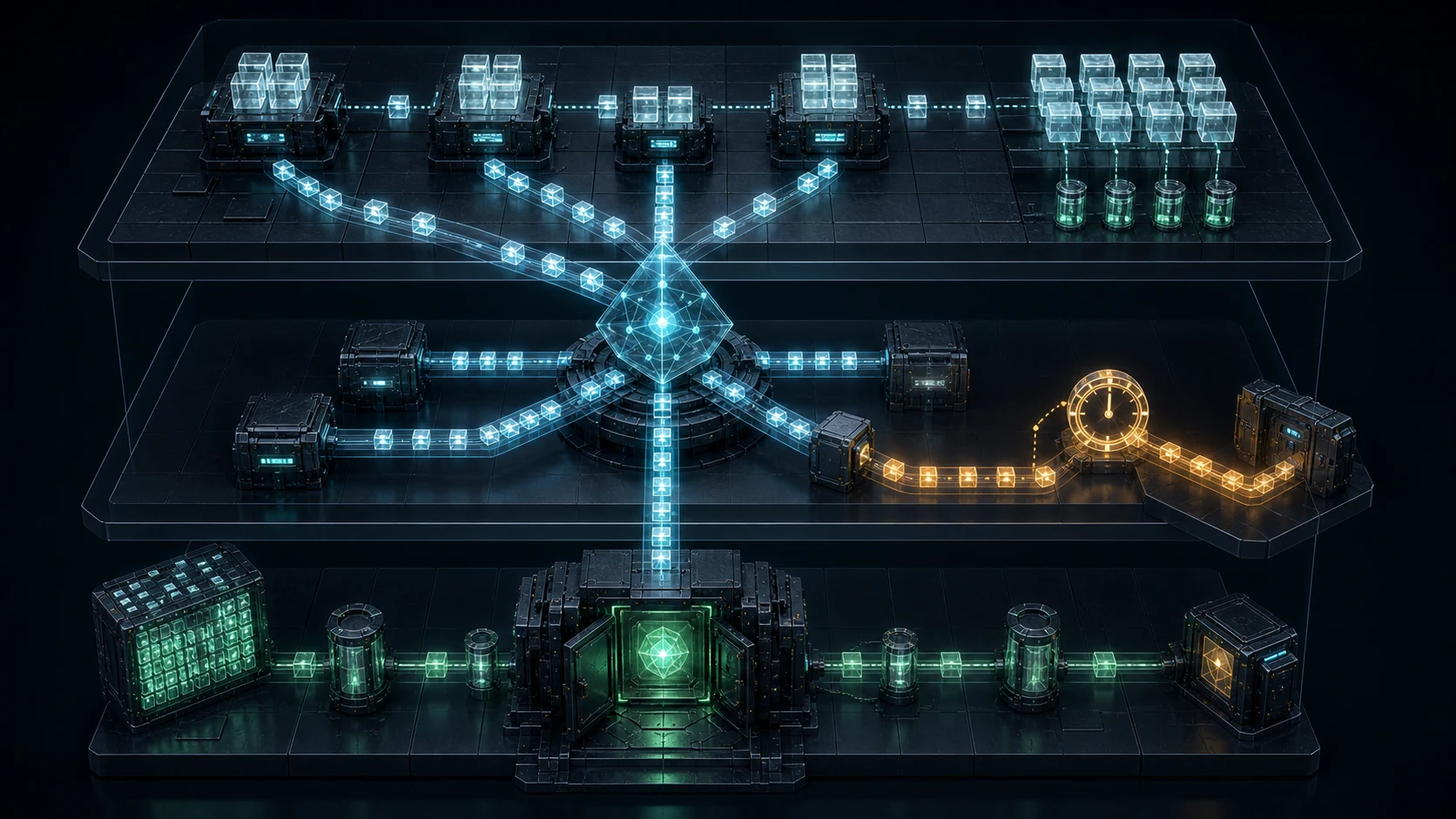
系统模型:三层状态根和两级证明
一个典型 L3 结算链路可以抽象为:
- L3 应用 Rollup `R3`:执行用户交易,生成状态根 `root3_t`; - L2 结算层 `R2`:接收 L3 批次、验证或聚合 L3 proof; - L1 终局层 `R1`:验证 L2 proof,提供最终经济安全; - 证明者 `P3/P2`:分别生成 L3 proof 和 L2 聚合 proof; - 用户、Solver、路由器:依赖不同层的状态完成交换、退款或再平衡。
普通链路可写成:
`tx -> root3_t -> proof3 -> root2_t -> proof2 -> root1_t`
若每个 L3 proof 都单独提交给 L2,L2 再把自己的批次提交到 L1,结算延迟和验证开销会叠加。嵌套证明的目标,是让外层证明验证内层 proof 的正确性,把许多 L3 状态转移压缩进一个 L2 可接受的证明,再由 L2 的证明进入 L1。
形式化地说,L2 不需要重新执行 L3,只需要验证一个声明:
`Verify3(proof3, vk3, oldRoot3, newRoot3, publicInputs3) = true`
然后 L2 把这个验证过程作为自己证明电路的一部分:
`Verify2(proof2, vk2, oldRoot2, newRoot2, commitment(proof3_result)) = true`
难点在于,`Verify3` 本身可能很贵。外层电路若要验证内层 verifier,必须处理验证密钥、public inputs、哈希、承诺打开和字段运算。递归证明的价值,是让“验证一个证明”的成本足够小,才有可能把多层状态压进一个终局证明里。
嵌套证明的核心成本:验证器也要被算术化
在普通 ZK 系统里,链上 verifier 是一段合约或虚拟机程序;在递归场景里,这段 verifier 要变成另一个证明系统里的电路。也就是说,外层证明不只是验证交易执行,还要证明“我正确验证了内层证明”。
这会带来三类成本。
第一,字段不匹配。若内层 proof 使用某个曲线或有限域,外层 proof 的基础域不同,外层电路就要模拟非原生字段运算。每一次标量乘法、配对检查、哈希置换或多项式承诺打开,都可能膨胀成 limb、range check、carry 和约束集合。
第二,验证密钥体积。`vk3` 不能随意变动,否则外层电路要支持多种 verifier。固定应用 L3 可以把验证密钥硬编码进聚合电路,降低灵活性换取成本;通用 L3 平台若允许每条应用链不同电路,就需要验证密钥注册、版本管理和电路升级规则。
第三,public inputs 绑定。内层 proof 必须绑定 chainId、L3 id、批次编号、old root、new root、消息根、withdrawal root 和 DA commitment。若绑定不完整,攻击者可能把一个上下文中有效的 proof 复用到另一个 L3 或另一个批次。
递归证明不是“多套 proof 套娃”这么简单,它更像一个严格的状态压缩协议。每一层都要明确哪些变量进入 public inputs,哪些状态根被上层接受,哪些消息可以跨层消费,哪些失败可以回滚。
批次聚合还会引入顺序问题。假设一个 L2 聚合批次同时包含 20 条 L3 的 proof,其中某一条 L3 的 proof 生成延迟或验证失败。聚合器可以跳过该 L3,也可以等待它补齐。跳过能减少整体延迟,但该 L3 上的用户会落后一个结算周期;等待能保持跨 L3 批次整齐,却会让一个应用链拖慢全部聚合。对路由器而言,`proofLag` 不只是某条链的平均证明时间,还包含聚合器的批次调度策略。
更麻烦的是验证密钥升级。应用 L3 往往希望快速升级 VM、费用模型或业务电路,但递归聚合电路依赖内层验证密钥。如果 `vk3` 发生变化,外层电路必须知道新版本,并防止旧订单在新规则下被解释。稳健设计应让每笔跨层消息绑定 `vkVersion`、`l3ChainId`、`batchId` 和 `stateTransitionType`。否则旧 proof 和新 proof 可能在同一消息通道中出现语义冲突。
资源瓶颈也会从链上 gas 转移到链下证明网络。L3 proof 生成、递归聚合、外层 proof 最终压缩,可能分别由不同证明者完成。若某个应用 L3 的证明任务过大,聚合器需要决定是等待、跳过、还是把它拆成更小批次。等待增加全局延迟;跳过影响该 L3 用户;拆批次增加 proof 数量和消息管理复杂度。证明聚合降低链上验证成本,但不会让 CPU、GPU、内存和证明者调度成本消失。
快轨互操作依赖预确认,但预确认不是最终性
L3 互操作通常会引入快轨。目标链或 Solver 可以基于 L3 排序器预确认(pre-confirmation)先给用户到账,随后等待证明链补齐。这样用户体验接近秒级,但安全性取决于预确认的可撤销边界。
可以把交易状态分成四层:
- `preconfirmedOnL3`:L3 排序器承诺会包含交易; - `provedToL2`:L3 proof 被 L2 接受; - `includedInL2Proof`:L2 聚合 proof 包含该 L3 状态; - `finalizedOnL1`:L1 接受最终证明或达到终局条件。
对小额交换,路由器可以让 Solver 承担预确认风险;对大额交换,必须等待 `provedToL2` 或更高层级。把四个状态都展示成“已完成”,会把结算风险隐藏给用户和 Solver。
预确认风险可以写成:
`expectedLoss = amount * P(reorg_or_noninclusion) * recoveryDelayCost`
这里的 `P` 不是固定常数,它取决于 L3 排序器去中心化程度、L2 接受窗口、DA 模式、证明者延迟和是否有强制入队/逃生路径。快轨越激进,用户体验越好,Solver 承担的库存和退款风险越高。
预确认还会产生排序器合谋问题。若 L3 排序器给 Solver 一个私下预确认,Solver 在目标链付款,但排序器随后没有把交易纳入可证明批次,Solver 只能依赖法律协议或声誉追偿。若预确认是公开承诺并写入 L2 可见队列,Solver 至少可以证明排序器违约。两种预确认在 UI 上都可能显示“秒级到账”,但风险完全不同。
因此,快轨不应只有一个布尔开关。路由器需要记录预确认的来源、是否公开、是否可惩罚、是否绑定批次、是否有强制包含路径。小额交易可以接受弱预确认,因为恢复成本低;大额交易应要求可公开验证的预确认,或者直接等待 L2 proof。把这些差异折算成报价,比在事故后解释“为什么这笔到账被撤销”更可控。
跨层消息和退款状态机
L3 到 L2/L1 的跨层消息至少要绑定四个对象:源状态根、消息根、消费标记和超时窗口。一个跨 L3 交换失败时,退款不能只看目标链是否到账,还要看消息是否被上层接受。
最小状态机可以写成:
`LockedOnSource`
`PreconfirmedOnTargetL3`
`ProvedToSettlementL2`
`FinalizedOrRefundable`
`Refunded`
关键转移是:
`refund(orderId) allowed iff now > deadline && !consumed[messageId] && proofOfNonFinalization(orderId)`
如果没有 `proofOfNonFinalization`,用户可能在目标 L3 已经收到资产后,又在源链拿退款;如果没有 `consumed[messageId]`,同一条跨层消息可能被重复消费;如果 deadline 没有绑定源链和目标链时钟,网络拥堵或证明延迟会制造争议。
对 AllSwap,这意味着跨 L3 路由的状态不能只记录一笔交易哈希。它至少应记录 `l3BatchId`、`proof3Status`、`l2AggregationStatus`、`finalityLevel`、`refundDeadline` 和 `messageConsumed`。这些字段决定用户应等待、退款、补交证明,还是让 Solver 继续承担风险。
`proofOfNonFinalization` 本身也不容易。链上合约擅长验证“某事件存在”,不擅长验证“某事件在某时间前没有最终完成”。实现上通常要借助超时、可挑战窗口或上层状态根:如果 deadline 之后仍没有可验证的 `messageConsumed`,源链允许退款;如果之后目标证明到达,必须被拒绝或转入仲裁。这个规则必须在订单创建时确定,不能在失败后临时判断。
消息消费顺序同样重要。若 L3 到 L2 的消息已被 L2 消费,但 L2 到 L1 的证明尚未终局,源链是否允许退款?保守模式等待 L1 终局,速度慢;激进模式在 L2 消费后承认完成,速度快但承担 L2 结算风险;折中模式让 Solver 先付款,用户状态显示为“已垫付,待终局”。这三个模式对应不同费用,不应混在同一个“完成”状态里。
数据可用性和 L3 专用化的取舍
L3 的一个卖点是应用专用。游戏、交易、支付、隐私应用可以选择不同 VM、不同 DA、不同费用模型。专用化会提高效率,也会让路由器更难统一评估风险。
如果 L3 使用 Rollup 模式,外部可以从上层恢复状态数据,退出和退款路径更清晰,但成本更高。若 L3 使用 Validium 或外部 DA,交易更便宜,状态恢复则依赖 DA 服务或委员会。若 L3 把数据放在 L2 之外,L2 接受 L3 proof 并不代表用户一定能拿到 witness。
这和第 48 篇讨论的 DAC 风险相同,只是多了一层证明嵌套。一个 L3 proof 可以证明某个 `newRoot3` 有效,但如果数据不可用,用户依旧可能无法构造退出 proof。递归不会修复数据可用性;它只压缩验证路径。
因此,L3 路由需要同时看两个维度:
- 证明最终性:proof3 是否被 L2 接受,proof2 是否进入 L1; - 数据恢复性:用户、钱包、索引器或路由器能否恢复状态 witness。
低费用路径如果只有前者没有后者,适合小额高频交易,不适合大额跨链结算。
还有一个存储层问题。应用 L3 可能只保存业务相关状态,例如订单簿、游戏资产或支付余额;跨链退款需要的却是跨层消息 root、用户余额 leaf、消费标记和历史批次索引。如果 L3 为了性能裁剪历史数据,用户可能在证明链最终完成前就失去构造退款 witness 的材料。L3 的归档策略因此也是路由风险的一部分。
对使用外部 DA 的 L3,数据可恢复性应像费用一样进入报价模型。一个路径可能在执行上极快,但 witness 下载需要依赖第三方 DA、DAC 或少数索引器。递归 proof 只证明状态有效,不证明这些 witness 在用户需要时可下载。对 AllSwap,最小要求是能在订单级别保存足够的恢复材料:源链锁定 proof、目标 L3 填单 proof、消息消费状态和退款 deadline。
对 AllSwap 路由的影响
AllSwap 可以把 L3 路由拆成三种风险级别。
- `fast-l3-fill`:基于 L3 预确认或 Solver 信用先到账; - `l2-proved-fill`:等待 L3 proof 被 L2 接受后再视为较安全; - `l1-finalized-fill`:等待完整证明链进入 L1 后再承认终局。
报价公式可以写成:
`routeScore = priceScore + speedScore - proofLagPenalty - daPenalty - refundAmbiguity`
`proofLagPenalty` 来自嵌套证明生成和聚合延迟,`daPenalty` 来自 L3 数据可用性模式,`refundAmbiguity` 来自失败后能否证明未最终完成。对 [/fees](/fees) 来说,L3 费用不只是 gas,还包括证明延迟、Solver 预垫库存成本和失败恢复成本。对 [/swap/usdt-erc20](/swap/usdt-erc20) 与 [/assets/usdc](/assets/usdc) 这类稳定币路径,大额交易应避免只看快轨报价。
UI 不必展示所有证明细节,但应区分“目标 L3 已预确认”“已被 L2 证明”“已在 L1 终局”。这三个状态对用户资产安全不是同一件事。若路径只达到预确认,用户看到的到账更像 Solver 信用;若已经 `provedToL2`,风险转移到 L2/L1 结算;若已 `finalizedOnL1`,退款争议才真正收敛。
后台风控可以进一步拆成限额规则。`fast-l3-fill` 适合低额、高频、可由 Solver 承担短期信用风险的交易;`l2-proved-fill` 适合中等金额,需要证明已进入 L2 结算轨道;`l1-finalized-fill` 适合高价值资产、机构级再平衡或对退款确定性要求极高的路径。这样用户不必学习递归证明,系统也不会把同一条 L3 路径当成所有金额都适用。
监控指标也应具体:`proof3Lag`、`aggregationQueueDepth`、`vkVersionMismatch`、`daRecoveryErrorRate`、`preconfirmReorgRate`、`refundDisputeCount`。如果 proof3 延迟上升,路由器应降低快轨额度;如果验证密钥版本不匹配,应暂停新订单;如果 DA 恢复失败率上升,应停止承诺即时退款。这些规则越自动化,异常时越少依赖人工客服解释复杂状态。
失败模式至少有四类。第一,L3 执行成功但 proof3 迟迟不生成,用户看到目标链状态变化,源链却不能确认最终完成。第二,proof3 已生成但 L2 聚合队列拥堵,Solver 库存被占用,报价会变差。第三,L2 聚合 proof 被 L1 延迟接受,退款和最终性之间出现长窗口。第四,L3 数据不可用,递归证明链可能仍能验证某些状态根,但用户无法构造订单级 witness。每一类失败都需要不同恢复动作,不能只用一个 `pending` 状态覆盖。
对产品而言,最重要的是把这些失败分解成可执行动作:等待证明、切换慢轨、降低额度、发起退款、提交 witness、或转入人工审计。若路由层缺少这些状态,嵌套证明越复杂,用户越难理解自己是否安全。AllSwap 的角色不是承诺所有 L3 都同样可靠,而是把证明链长度、DA 模式、预确认强度和退款可验证性转换成可比较的路由结果。
金额分层应成为默认策略。低额交易可以优先速度,把预确认风险交给报价和限额吸收;中额交易应等待 L2 接受 L3 proof;高额交易需要 L1 终局或等价的保险/保证金覆盖。这样快轨不是被禁用,而是被放在它适合的风险区间内。 否则,低费用会掩盖结算层级差异,最终把复杂性留给退款流程。 这也是跨 L3 路由必须保留完整结算状态的原因。 没有这些状态,用户无法判断资金处于执行、证明还是退款阶段。 也无法正确评估等待成本。
仍未解决的问题
第一,递归证明的最终压缩成本仍是瓶颈。L3 越多、验证密钥越多、public inputs 越复杂,聚合电路越难保持低延迟。
第二,跨层消息标准不统一。L3 到 L2、L2 到 L1 的消息根、消费标记和超时语义各不相同,聚合器难以用同一套状态机解释。
第三,预确认缺少机器可读风险描述。排序器承诺、证明者 SLA、DA 模式和强制入队能力应形成 `settlementProfile`,否则路由器只能用粗糙标签判断。
第四,L3 失败后的退款归因复杂。失败可能发生在 L3 执行、proof3 生成、L2 聚合、L1 最终验证、DA 恢复或 Solver 履约任一环节。没有细粒度状态,用户只能看到“处理中”。
第五,应用专用 L3 的升级治理会影响 proof 安全。若验证密钥、VM 版本或 DA 模式可以快速升级,旧订单和未结算消息必须绑定升级前后的规则,否则跨链退款会出现语义漂移。
References
[1] ZK-Rollups, Ethereum.org, 2026, https://ethereum.org/en/developers/docs/scaling/zk-rollups/
[2] What kinds of layer 3s make sense?, Vitalik Buterin, 2022, https://vitalik.eth.limo/general/2022/09/17/layer_3.html
[3] Blockchain Layer 3, StarkWare, 2022, https://starkware.co/blog/blockchain-layer-3/
[4] Recursive Circuit Proving Efficiency, StarkWare, 2026, https://starkware.co/blog/minutes-to-seconds-efficiency-gains-with-recursive-circuit-proving/
[5] ZKsync ZK Stack, ZKsync Docs, 2026, https://docs.zksync.io/zk-stack
[6] ZKsync Chains, ZKsync Docs, 2026, https://docs.zksync.io/zk-stack/zk-chains
[7] Arbitrum Chains Introduction, Arbitrum Docs, 2026, https://docs.arbitrum.io/launch-arbitrum-chain/overview/introduction
[8] Polygon Agglayer Overview, Polygon Docs, 2026, https://docs.polygon.technology/agglayer/
[9] Celestia Data Availability, Celestia Docs, 2026, https://docs.celestia.org/learn/celestia-101/data-availability/
[10] L2BEAT Scaling Summary and Risk Framework, L2BEAT, 2026, https://l2beat.com/scaling/summary
常见问题
L3 为什么还需要嵌套 ZK 证明?
因为 L3 状态通常要先被 L2 接受,再通过 L2 证明进入 L1。嵌套 ZK 证明把内层 L3 proof 的验证结果压缩进外层证明,降低多层结算的验证成本。
L3 预确认和最终性有什么区别?
预确认通常是排序器或 Solver 对交易将被包含的承诺,用户体验很快,但仍可能被撤销或延迟。最终性需要 L3 proof 被 L2 接受,甚至进一步进入 L1 终局。
递归证明能解决 L3 数据可用性问题吗?
不能。递归证明只能压缩验证路径,不能保证用户拿得到状态 witness。若 L3 使用外部 DA 或 Validium 模式,退出和退款仍依赖数据可恢复性。
AllSwap 路由为什么要区分 L3 的证明状态?
同一笔交换处于预确认、L2 已证明和 L1 已终局时,退款风险完全不同。路由系统应把 proof lag、DA 模式和 refund ambiguity 纳入报价和限额。
L3 适合大额跨链交易吗?
取决于结算层级和数据可用性。小额交易可接受快轨和 Solver 信用;大额交易应等待 L2 proof 或 L1 终局,并确认失败后有可证明退款路径。