L3 speed does not erase settlement risk
Modular Layer 3s are attractive because they let applications specialize execution, fees, data availability, and state layout while still anchoring to a broader L2/L1 security stack. The uncomfortable part is that settlement becomes longer, not shorter. An L3 state root must be accepted by an L2 settlement layer, and the L2 state must then reach L1 finality. Without nested ZK proofs or recursive proof aggregation, the gap between "the user sees a completed action" and "the settlement layer can verify it" can become large.
For [AllSwap cross-chain swap](/exchange-swap), an L3 is not merely another cheap network. A cross L2/L3 swap has to answer several concrete questions. Is the target L3 fill only preconfirmed by a sequencer? Has the L3 proof been accepted by the L2? Has the L2 aggregate proof reached the L1? If a proof stalls at any layer, which root controls the refund, solver claim, or asset exit?
This article focuses on modular L3 settlement with nested ZK proofs. It does not treat every appchain, sidechain, or centralized execution environment as the same design. The core conclusion is narrow: nested proofs can compress verification and reduce the cost of multi-layer settlement, but they do not remove data availability, preconfirmation, proof-lag, message-consumption, and refund-attribution problems.
System model: three roots and two proof layers
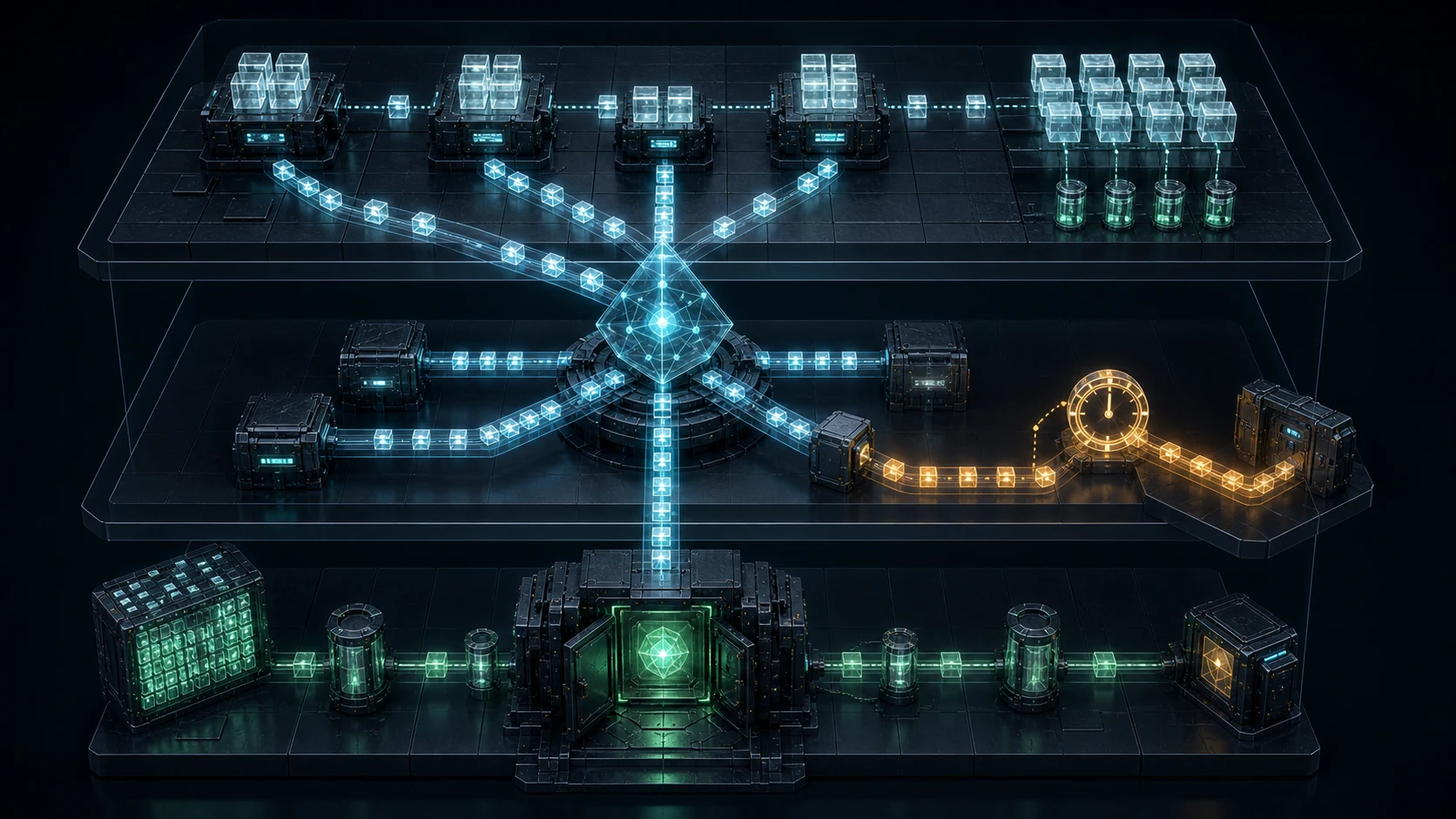
A simplified L3 settlement stack has five moving parts:
- Application Rollup `R3`, which executes transactions and produces `root3_t`. - Settlement L2 `R2`, which accepts L3 batches and verifies or aggregates L3 proofs. - Finality L1 `R1`, which verifies the L2 proof or accepts the L2 settlement state. - Provers `P3` and `P2`, which generate L3 proofs and L2 aggregate proofs. - Users, solvers, and routers, which decide whether a swap is filled, refundable, or final.
The normal path is:
`tx -> root3_t -> proof3 -> root2_t -> proof2 -> root1_t`
If every L3 proof is submitted separately to L2, and L2 later submits its own proof to L1, cost and latency compound. Nested proofs aim to compress this chain. The L2 does not re-execute the L3; it verifies a statement about the L3 transition:
`Verify3(proof3, vk3, oldRoot3, newRoot3, publicInputs3) = true`
The L2 proof then includes that verification result:
`Verify2(proof2, vk2, oldRoot2, newRoot2, commitment(proof3_result)) = true`
The difficult part is that `Verify3` itself must be represented inside the outer proof. In ordinary deployment, the verifier is a contract or VM program. In recursive settlement, the verifier becomes a circuit. That circuit has to handle verification keys, public inputs, commitments, hashes, field operations, and context binding.
Recursion is not simply stacking proofs. It is a state-compression protocol. Each layer must define which public inputs matter, which roots are accepted by the parent layer, which messages may be consumed, and which failures can be rolled back.
The verifier becomes part of the proving workload
Nested proofs move cost rather than eliminating it. The chain verifies fewer proofs onchain, but the proving network has to prove that verification happened correctly.
The first cost is field mismatch. If the inner proof system uses one curve or finite field and the outer proof system uses another, the outer circuit may need non-native arithmetic. Scalar multiplication, commitment openings, hash permutations, and pairing checks can become limbs, range checks, carries, and many more constraints than the high-level protocol suggests.
The second cost is verification-key management. A fixed application L3 can hardcode `vk3` into the aggregation circuit and reduce flexibility. A general L3 platform that supports many application-specific circuits needs verification-key registration, versioning, upgrade rules, and replay boundaries. Every cross-layer message should bind `vkVersion`, `l3ChainId`, `batchId`, and the transition type. Otherwise, an old proof and a new proof can be interpreted under different semantics.
The third cost is public-input binding. An L3 proof should bind chain id, L3 id, batch id, old root, new root, message root, withdrawal root, and data-availability commitment. Without those bindings, a proof that is valid for one L3 or batch can become dangerous when replayed in another context.
Batch aggregation adds scheduling risk. Suppose one L2 aggregate batch is supposed to include proofs from 20 L3s. If one L3 proof is late or invalid, the aggregator can wait, skip that L3, or split the batch. Waiting increases latency for everyone. Skipping leaves one L3 behind. Splitting increases proof count and message-management overhead. A router's `proofLag` estimate is therefore not only the average proving time of one L3; it also includes aggregation policy.
There is a resource bottleneck behind the gas savings. L3 proof generation, recursive aggregation, and final proof compression may be handled by different proving services. A heavy application L3 can delay aggregation or force smaller batches. Recursion reduces onchain verification cost, but it does not make CPU, GPU, memory, and prover-scheduling costs disappear.
The engineering effect is that proof markets become part of settlement risk. If proof generation is centralized, a single overloaded prover can delay a whole application L3. If proving is decentralized, the system needs task assignment, result verification, aggregation ordering, and reward rules. A route that looks cheap during normal load can become expensive when proving capacity is congested. For cross-chain swaps, the relevant question is not "can this L3 eventually prove?" but "can it prove inside the refund and inventory window that this route assumes?"
Verification-key upgrades also need explicit migration rules. An application L3 may want to upgrade its VM, fee logic, precompile set, or application circuit. If the new verifier key is accepted immediately, unsettled messages created under the old verifier may be interpreted under a different transition rule. If upgrades are delayed too long, security fixes and performance upgrades become slow. A practical compromise is versioned settlement: every order binds the verifier version active at order creation, and parent-layer contracts keep enough verifier history to settle old messages safely.
Fast lanes depend on preconfirmation, not finality
L3 interoperability usually wants a fast lane. A target chain or solver may fill the user based on L3 sequencer preconfirmation, then wait for the proof chain to catch up. The user experience can feel near-instant, but safety depends on what the preconfirmation actually means.
The settlement states should be separated:
- `preconfirmedOnL3`: the L3 sequencer promises inclusion. - `provedToL2`: the L3 proof has been accepted by the L2. - `includedInL2Proof`: the L2 aggregate proof includes the relevant L3 state. - `finalizedOnL1`: the final proof or settlement condition is accepted on L1.
Small swaps may be filled on preconfirmation if the solver prices the risk. Large swaps should wait for `provedToL2` or stronger. Treating all four states as "complete" hides settlement risk from both the user and the solver.
The preconfirmation risk can be modeled as:
`expectedLoss = amount * P(reorg_or_noninclusion) * recoveryDelayCost`
`P` is not a protocol constant. It depends on the L3 sequencer model, L2 acceptance window, data-availability mode, prover delay, forced-inclusion path, and escape path. The more aggressive the fast lane, the better the user experience and the more inventory/refund risk the solver carries.
Preconfirmation can also be private or public. If an L3 sequencer gives a solver a private preconfirmation and later fails to include the transaction, the solver may have little more than a commercial dispute. If the preconfirmation is public, batch-bound, and visible to the L2, the solver has objective evidence. Both can look like fast settlement in a UI, but they have different risk profiles.
A route engine should therefore store where the preconfirmation came from, whether it is public, whether it is slashable or punishable, whether it is bound to a batch, and whether forced inclusion exists. Low-value routes can tolerate weak preconfirmation. High-value routes should require public preconfirmation or wait for proof acceptance.
The difference matters most when a solver prefunds the destination side. If the target L3 preconfirms a fill and the solver pays the user, the solver now holds settlement risk until proof acceptance. If proof generation is delayed, the solver's inventory is locked. If the L3 sequencer fails to include the transaction, the solver may need to unwind through a refund or dispute path. Rational solvers price that uncertainty into quotes or lower route limits. A route engine that hides the preconfirmation layer will eventually expose the user to worse spreads without explaining why.
Preconfirmation should therefore be an input to the fee model. Private preconfirmation, public preconfirmation, L2-visible inclusion queue, and fully proved state should not have the same price. The user does not need to see the whole taxonomy, but the quote should reflect it.
Cross-layer messages need a refund state machine
L3-to-L2/L1 messages have to bind at least four objects: source root, message root, consumed marker, and timeout window. A failed cross-L3 swap cannot be refunded only because the target chain did not show a balance in the UI. The refund must depend on whether the message was consumed by the relevant settlement layer.
A minimal state machine is:
`LockedOnSource`
`PreconfirmedOnTargetL3`
`ProvedToSettlementL2`
`FinalizedOrRefundable`
`Refunded`
The critical transition is:
`refund(orderId) allowed iff now > deadline && !consumed[messageId] && proofOfNonFinalization(orderId)`
Without `proofOfNonFinalization`, a user could receive the target asset and later claim a source refund. Without `consumed[messageId]`, the same cross-layer message can be consumed twice. Without a deadline bound to both source and target timing assumptions, prover delay or network congestion turns into a dispute.
The non-finalization proof is the hard part. Contracts are good at verifying that something exists; they are worse at proving that something did not finalize before a deadline. Designs usually rely on timeouts, challenge windows, or accepted parent-layer roots. If the deadline passes with no verifiable `messageConsumed`, the source chain allows refund. If a target proof arrives later, it must be rejected or routed into arbitration. The rule has to be fixed at order creation, not invented during the incident.
There is also a policy choice. If the L3-to-L2 message is consumed but the L2-to-L1 proof is not final, should the source side allow refund? Conservative mode waits for L1 finality. Aggressive mode treats L2 consumption as enough. A middle path lets the solver prefund and labels the user state as "filled, pending finality." These modes have different costs and should not be hidden behind one completed state.
Message replay is another practical risk. A withdrawal root or message root from one L3 should not be consumable on a sibling L3 or on a later verifier version. Each message should bind chain id, application id, proof version, sender, receiver, token, amount, deadline, and settlement path. The cost of these bindings is more public input and more circuit complexity; the cost of omitting them is cross-domain replay.
Refund deadlines also need a clock hierarchy. The source chain clock, target L3 clock, settlement L2 clock, and L1 finality clock are not the same clock. If the deadline is measured only on the source chain, a congested proof pipeline can make honest fills look late. If it is measured only on the target L3, users may be unable to enforce refunds from the source side. A robust order should define which clock controls refund eligibility and how proof delay is handled.
Data availability still controls recovery
One reason L3s are useful is specialization. A gaming L3, trading L3, payment L3, or privacy L3 can choose a specific VM, DA mode, fee model, and state layout. That specialization improves efficiency and complicates routing.
If an L3 publishes data in a Rollup-like way, outside observers can reconstruct state and exits are easier to reason about. If the L3 uses Validium-style data, an external DA layer, or a small indexing network, execution may be cheaper while state recovery depends on that data path. An L2 accepting an L3 proof does not prove that users can download the witness they need.
This repeats the Validium lesson in a nested setting. A valid L3 proof can show that `newRoot3` follows from `oldRoot3`. If transaction data or state diffs are unavailable, the user may still be unable to construct a withdrawal or refund witness. Recursion compresses verification; it does not fix data availability.
L3 route risk therefore has two dimensions:
- Proof finality: whether `proof3` is accepted by L2 and whether `proof2` reaches L1. - Data recoverability: whether users, wallets, indexers, or routers can reconstruct state witnesses.
There is also a storage issue. Application L3s may retain only application-specific state, while cross-chain refunds require message roots, user balance leaves, consumed markers, and historical batch indexes. If an L3 prunes history before the proof chain is fully finalized, a user can lose the material needed to make a refund argument. Archival policy is part of settlement risk.
For an AllSwap-style route, the minimum recoverable package should include the source lock proof, target L3 fill proof, message-consumption status, data-availability reference, and refund deadline. A route that has cheap execution but weak witness recovery should be treated as small-value or high-risk, not as equivalent to a Rollup-grade path.
Archival policy should be tested, not assumed. If an L3 prunes old state aggressively, the router should know how long order witnesses remain reconstructable. If an external DA layer is used, the router should know the namespace, commitment, or blob reference that anchors the fill. If a wallet must store user-side state, the route should not promise self-service recovery unless the wallet actually persisted the required witness. A low execution fee is not enough when the recovery material is missing.
This is where L3 specialization cuts both ways. A trading L3 can optimize its state layout around order books and matching. A game L3 can optimize around assets and player state. A payment L3 can optimize around balances and account abstraction. But a cross-chain refund system needs a common recovery envelope. Without that envelope, each application-specific L3 becomes a bespoke integration, and route safety depends on offchain operational knowledge.
What this means for AllSwap routing
AllSwap can split L3 routes into three practical risk levels:
- `fast-l3-fill`: the user is filled based on L3 preconfirmation or solver credit. - `l2-proved-fill`: the fill is treated as safer after the L3 proof is accepted by L2. - `l1-finalized-fill`: the route waits for the full proof chain to reach L1 finality.
A route score can include nested-settlement risk:
`routeScore = priceScore + speedScore - proofLagPenalty - daPenalty - refundAmbiguity`
`proofLagPenalty` comes from L3 proving and L2 aggregation delay. `daPenalty` comes from L3 data-availability mode. `refundAmbiguity` comes from whether failure can be proven and unwound without trusting an operator.
For [/fees](/fees), L3 cost is not only gas. It includes proof lag, solver inventory cost, and failed-route recovery. For stablecoin routes such as [/swap/usdt-erc20](/swap/usdt-erc20) and [/assets/usdc](/assets/usdc), large transfers should not be evaluated only by the fastest quote. The route engine should know whether the target state is preconfirmed, proved to L2, or finalized on L1.
The UI does not need to show every circuit detail, but it should not flatten these states. If the route is only preconfirmed, the user is relying on solver credit and sequencer behavior. If it is `provedToL2`, the risk moves to L2/L1 settlement. If it is `finalizedOnL1`, refund disputes are much narrower.
Limits should follow the same structure. `fast-l3-fill` fits low-value, high-frequency payments where the solver can absorb short-term risk. `l2-proved-fill` fits medium-size swaps. `l1-finalized-fill` fits high-value assets or routes where refund certainty matters more than speed. This makes the fast lane useful without pretending it is the same as final settlement.
Monitoring signals should be explicit: `proof3Lag`, `aggregationQueueDepth`, `vkVersionMismatch`, `daRecoveryErrorRate`, `preconfirmReorgRate`, and `refundDisputeCount`. If proof3 lag rises, fast-lane limits should fall. If verification-key versions mismatch, new orders should pause. If DA recovery errors rise, instant refund promises should be disabled. Otherwise nested settlement complexity becomes a support problem instead of a routing parameter.
A useful route policy is tiered by amount. Low-value transfers can optimize for speed and use preconfirmation, as long as solver exposure and refund handling are priced. Medium-value transfers should wait for L2 acceptance of the L3 proof. High-value transfers should require L1 finality or equivalent insurance and collateral. The fast lane is not unsafe by definition; it is unsafe when used outside its risk budget.
The same tiering applies to UI language. A user should not have to read circuit documentation, but "received on L3," "proved to L2," and "final on L1" should not be treated as synonyms. Those labels decide whether the next action is wait, refund, submit witness, or escalate to solver settlement. Without them, the system pushes complex settlement state into customer support at the worst possible moment.
Open problems
The first open problem is final compression cost. More L3s, more verification keys, and more public inputs make aggregation circuits harder to keep fast.
The second problem is cross-layer message standardization. L3-to-L2 and L2-to-L1 systems use different message roots, consumed markers, and timeout semantics, which makes unified routing state hard.
The third problem is machine-readable preconfirmation risk. Sequencer promises, prover service level, DA mode, and forced-inclusion support should become a `settlementProfile`; otherwise route engines rely on rough labels.
The fourth problem is refund attribution. A failed route can fail at L3 execution, proof3 generation, L2 aggregation, L1 verification, DA recovery, or solver fill. Each failure has a different recovery path.
The fifth problem is application-chain upgrades. If an L3 can quickly change its VM, verification key, or DA mode, old orders and unsettled messages must stay bound to the rules under which they were created.
References
[1] ZK-Rollups, Ethereum.org, 2026, https://ethereum.org/en/developers/docs/scaling/zk-rollups/
[2] What kinds of layer 3s make sense?, Vitalik Buterin, 2022, https://vitalik.eth.limo/general/2022/09/17/layer_3.html
[3] Blockchain Layer 3, StarkWare, 2022, https://starkware.co/blog/blockchain-layer-3/
[4] Recursive Circuit Proving Efficiency, StarkWare, 2026, https://starkware.co/blog/minutes-to-seconds-efficiency-gains-with-recursive-circuit-proving/
[5] ZKsync ZK Stack, ZKsync Docs, 2026, https://docs.zksync.io/zk-stack
[6] ZKsync Chains, ZKsync Docs, 2026, https://docs.zksync.io/zk-stack/zk-chains
[7] Arbitrum Chains Introduction, Arbitrum Docs, 2026, https://docs.arbitrum.io/launch-arbitrum-chain/overview/introduction
[8] Polygon Agglayer Overview, Polygon Docs, 2026, https://docs.polygon.technology/agglayer/
[9] Celestia Data Availability, Celestia Docs, 2026, https://docs.celestia.org/learn/celestia-101/data-availability/
[10] L2BEAT Scaling Summary and Risk Framework, L2BEAT, 2026, https://l2beat.com/scaling/summary
FAQ
Why do Layer 3 systems need nested ZK proofs?
An L3 state usually needs to be accepted by an L2 before the L2 state reaches L1. Nested ZK proofs compress the verification of inner L3 proofs into an outer proof, reducing multi-layer settlement cost.
What is the difference between L3 preconfirmation and finality?
Preconfirmation is a sequencer or solver promise that a transaction will be included. Finality requires the L3 proof to be accepted by L2, and often the L2 proof to reach L1.
Do recursive proofs solve L3 data availability risk?
No. Recursive proofs compress verification, but they do not guarantee that users can obtain state witnesses. If an L3 uses external DA or Validium-style data, exits still depend on recoverable data.
Why should AllSwap distinguish L3 proof states?
A swap that is only preconfirmed has different refund risk than one proved to L2 or finalized on L1. Route scoring should price proof lag, DA mode, and refund ambiguity.
Are L3 routes suitable for large cross-chain swaps?
It depends on settlement level and data availability. Small swaps can use fast lanes and solver credit; large swaps should wait for L2 proof or L1 finality and require a provable refund path.